셀레니움 활용, 네이버 블로그 크롤링 및 방문자 수 자동 수집하기!
안녕하세요! 크롤링이라는 용어에 대해 들어본 적이 있으신가요? 일상적으로는 천천히 기어가는 것을 의미하지만, IT와 프로그래밍에서는 완전히 다른 뜻을 가지고 있습니다. 프로그래밍에서 크롤링은 특정 프로그램을 사용하여 웹사이트를 자동으로 탐색하고, 필요한 데이터를 수집하는 작업을 의미합니다. 이 과정은 대규모 데이터 수집이나 웹사이트 분석에 매우 유용하게 사용됩니다.
이번 포스팅에서는 셀레니움(Selenium)이라는 도구를 사용해 네이버 블로그의 데이터를 크롤링하는 방법을 알아보겠습니다. 특히 블로그의 방문자 수 데이터를 수집하는 방법에 집중할 예정입니다. 이 과정은 파이썬(Python) 프로그래밍 언어를 기반으로 진행되므로, 파이썬이 설치되어 있지 않은 분들은 먼저 설치 후 따라오시면 됩니다. 파이썬은 간단하면서도 강력한 프로그래밍 언어로, 다양한 웹 크롤링 작업에 널리 사용되고 있습니다.
셀레니움 패키지 설치하기
크롤링 작업을 시작하려면 먼저 필요한 파이썬 패키지를 설치해야 합니다. 셀레니움은 웹 브라우저를 자동으로 제어할 수 있게 해주는 강력한 라이브러리로, 웹 페이지에서 데이터를 추출하거나 특정 작업을 자동으로 수행할 수 있습니다. 먼저, 윈도우 검색 창에 'cmd'를 입력하여 '명령 프롬프트'를 실행해 주세요. 이 명령 프롬프트는 파이썬 패키지를 설치하고 관리하는 데 사용됩니다.

명령 프롬프트 창이 열리면 다음 명령어를 입력하여 셀레니움 패키지를 설치합니다. 이 명령어는 파이썬의 패키지 관리 시스템인 pip를 통해 셀레니움을 다운로드하고 설치하는 역할을 합니다.
pip install selenium
네이버 블로그에 접속하기
셀레니움이 설치되었으면, 이제 본격적으로 네이버 블로그에 접속해 데이터를 수집해 보겠습니다. 파이썬 인터프리터를 실행한 후, 아래의 코드를 작성해 주세요. 여기서 주의할 점은 블로그의 모바일 주소를 사용해야 한다는 것입니다. 모바일 페이지에서는 블로그 방문자 수와 같은 데이터를 쉽게 확인할 수 있습니다. 모바일 주소는 블로그 URL 앞에 'm.'을 추가하면 됩니다.
이 예시에서는 네이버 블로그팀의 공식 블로그를 사용하겠습니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://m.blog.naver.com/blogpeople')
위의 코드에서는 Chrome 웹드라이버를 사용해 네이버 블로그에 접속하는 방법을 보여줍니다. 셀레니움은 다양한 브라우저를 지원하지만, 여기서는 가장 널리 사용되는 크롬을 예로 들었습니다. 해당 블로그 페이지에 접속한 후, 원하는 데이터를 추출할 준비를 마칩니다.
블로그에서 정보 경로 찾기
이제 블로그 페이지에서 원하는 정보를 가져올 수 있도록, 해당 데이터의 위치를 알아내야 합니다. 이 단계에서는 약간의 수작업이 필요합니다. 크롤러가 정확한 정보를 수집하려면, 데이터를 담고 있는 요소의 경로(XPath)를 정확히 지정해 줘야 합니다. 이 과정은 처음에는 다소 복잡하게 느껴질 수 있지만, 차근차근 따라하면 어렵지 않게 완료할 수 있습니다.
여기에서는 크롬 브라우저를 예로 들어 설명드리겠습니다. 먼저, 크롤링할 블로그 주소에 접속한 후 'F12' 키를 눌러 개발자 도구를 엽니다. 개발자 도구는 웹 페이지의 소스 코드를 분석하고 수정할 수 있는 유용한 도구로, 크롤링 작업에서도 중요한 역할을 합니다. 개발자 도구 창이 오른쪽에 나타날 것입니다.
그 다음, 개발자 도구에서 화살표 모양의 '요소 선택' 버튼을 클릭해 주세요. 이 버튼을 사용하면 웹 페이지에서 특정 요소를 선택할 수 있습니다.
이제 방문자 수와 같은 원하는 데이터를 포함하고 있는 페이지 요소를 클릭합니다. 방문자 수를 표시하는 부분을 클릭해 보세요. 그러면 개발자 도구에서 해당 요소의 HTML 코드가 강조되어 표시될 것입니다.
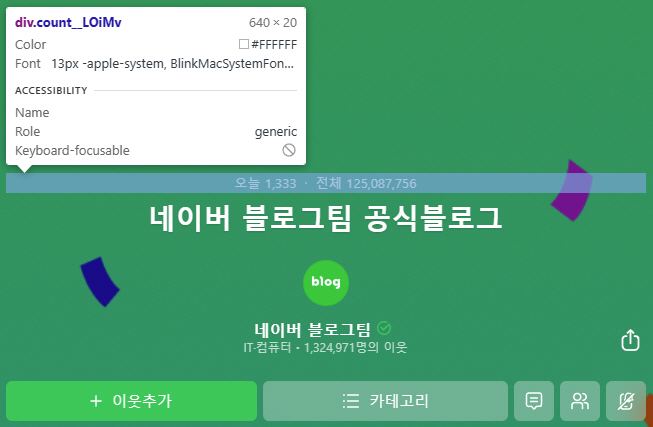
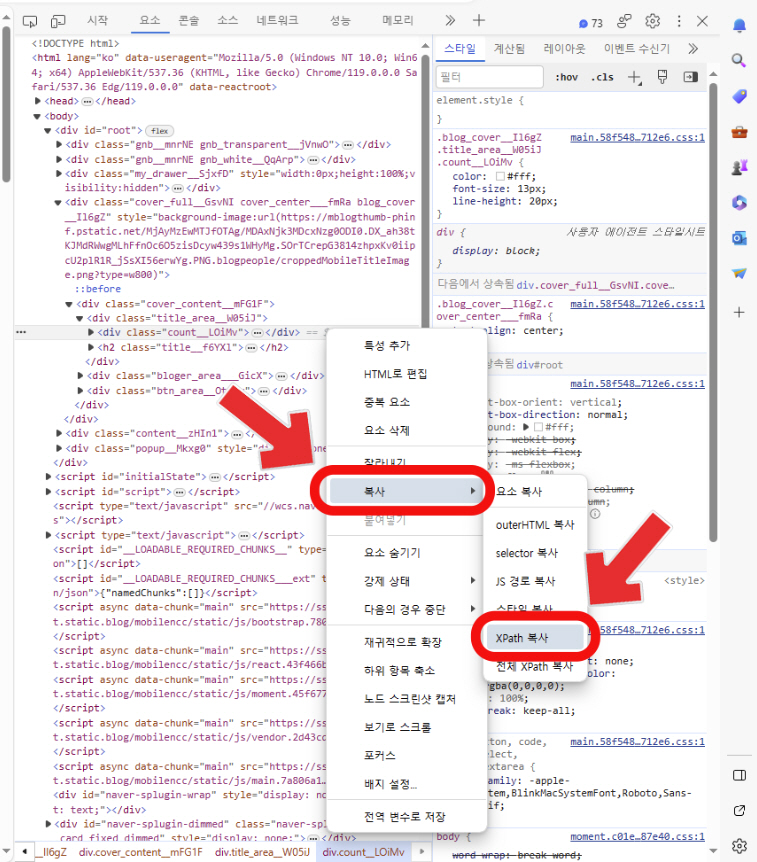
이렇게 특정 요소가 선택되면, 개발자 도구에서 해당 위치로 이동합니다. 선택한 요소의 HTML 코드 부분을 우클릭하고, 나타나는 메뉴에서 '복사' 옵션을 선택한 후 'XPath 복사'를 클릭하세요. 이제 해당 요소의 경로를 복사한 것입니다.
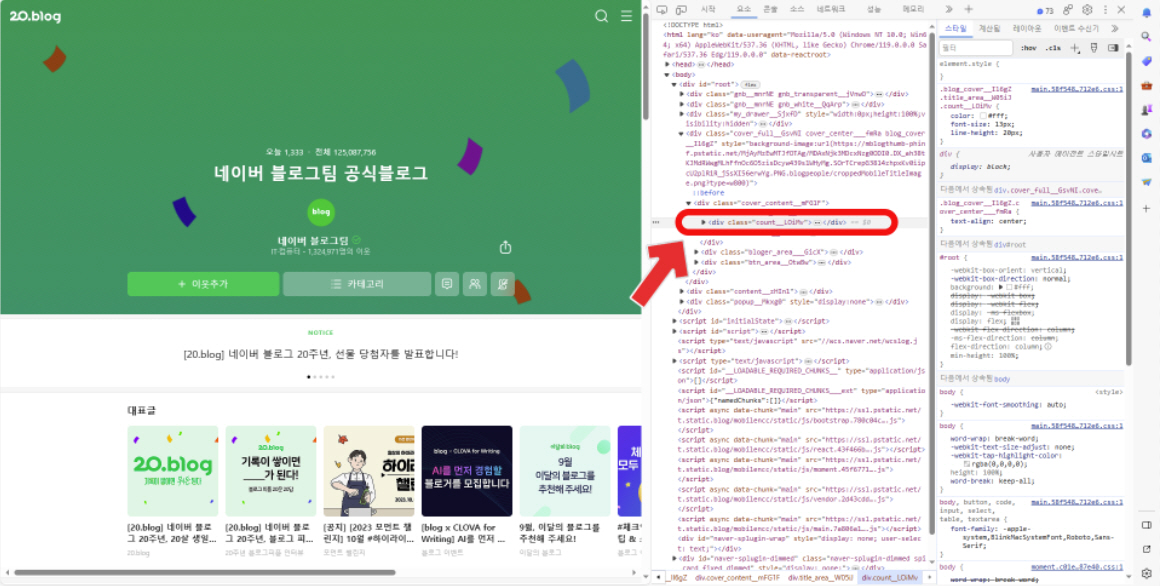
복사한 XPath는 우리가 원하는 데이터를 정확히 지정할 수 있게 해줍니다. 이제 이 경로를 사용해 크롤링 작업을 계속 진행할 수 있습니다.
크롤러에 경로 입력하기
이제 크롤러에게 방금 복사한 경로를 알려줄 차례입니다. 아래와 같이 코드를 작성해 주세요. 여기에서 '//*[@id="root"]/div[4]/div/div[1]/div' 부분이 이전에 복사한 XPath입니다. 이 코드를 사용하면 방문자 수 데이터를 추출할 수 있습니다.
elem=driver.find_element(By.XPATH, '//*[@id="root"]/div[4]/div/div[1]/div')
visitor=elem.text
print(visitor)
이 코드를 실행하면 크롤러가 네이버 블로그의 방문자 수를 가져오게 됩니다. 데이터 수집이 완료되면, 이 데이터를 다양한 방식으로 분석하거나 저장할 수 있습니다. 이 방법은 웹 페이지의 구조를 이해하고, 필요한 데이터를 자동으로 수집하는 데 매우 유용합니다.

| 네이버 블로그 이웃 자동 추가하기, 파이썬 셀레니움으로 자동화 블로그 관리 방법 (1) | 2024.08.20 |
|---|---|
| 파이썬 설치와 비주얼 스튜디오 코드(VS Code) 설정 방법 완벽 안내 (0) | 2024.08.20 |
| 포토샵 오류 해결방법 '고급 개체를 직접 편집할 수 없으므로 요청한 사항을 완료할 수 없습니다.' 과 고급 개체 사용 시 알아두면 좋은 팁! (0) | 2024.08.19 |
| 그림판 활용 서명 및 사인 파일 손쉽게 제작하기 (0) | 2024.08.19 |
| 그림판 gif 간단한 움짤 만드는 방법 (0) | 2024.08.17 |




댓글